Chapter 6 Basic Quantitative Geography
From chapter 3 to 5, we have learned how to make maps and do spatial operations, they are all fundamental and vital contents regarding spatial analysis. The operations we have learned could help us identify what the space “looks like”; however, up to now, we have no idea about “what space tells.” Hence, this chapter would introduce the basic theory and application of quantitative geography. We would learn the point patterns and spatial auto correlation, which are relatively simple in this field, and can also apply to the analysis on transportation issue. Note that there are much more to explore other than these two elements, if interested, please refer to the textbook Spatial Data Analysis - An Introduction For GIS Users.
In this chapter, we require a preliminary knowledge on statistics, especially the concept of hypothetical test.
6.1 Point Patterns Analysis
6.1.1 Basic measures
Two commonly used summary measures of point pattern analysis are the mean center and the standard distance. The mean center of a point pattern implies the central tendency of the whole points. It is simply the mean of the x and y coordinates:
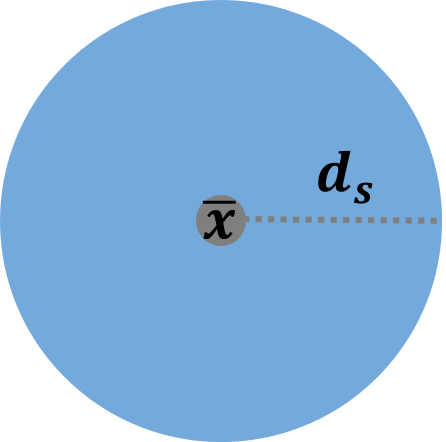
\[\bar{\bf{x}}=(\frac{\sum_{i=1}^n \ {x_i}}{n}, \quad \frac{\sum_{i=1}^n \ {y_i}}{n})\] In the equation above, the bold letter \(\bar{\bf{x}}\) represents a vector of X and Y coordinates, and the number of points is \(n\). Besides mean, the other basic statistic is “standard deviation,” that is, the standard distance in the spatial analysis. This standard distance can be interpreted as the dispersion around the mean center:
\[{d_s}=\sqrt{\frac{\sum_{i=1}^n \ {{(x_i-\mu_x)}^2+{(y_i-\mu_y)}^2}}{n}}\]
As for the center analysis, we may come up with the function st_centroid. However, the function can only use on the center of polygon, it can not retrieve the center of multiple points. An easiest way is to do the summary of X and Y coordinates of the whole points. Take Taipei YouBike for instance. Data needed has been downloaded previously. You placed the file in the same directory as the R script file. Click here to re-download the file if it is lost. First, we need to convert X and Y coordinates by using st_coordinates(), and then, just calculate the mean and standard deviation on the data converted.
# import the shapefile
taipei_youbike=read_sf("./data/taipei_youbike/taipei_youbike.shp")
# retrieve the coordinated of the points
taipei_youbike_coor=st_coordinates(taipei_youbike)
# calculate mean and standard deviation
apply(taipei_youbike_coor, 2, FUN=mean)## X Y
## 304679.5 2771747.9apply(taipei_youbike_coor, 2, FUN=var)^0.5## X Y
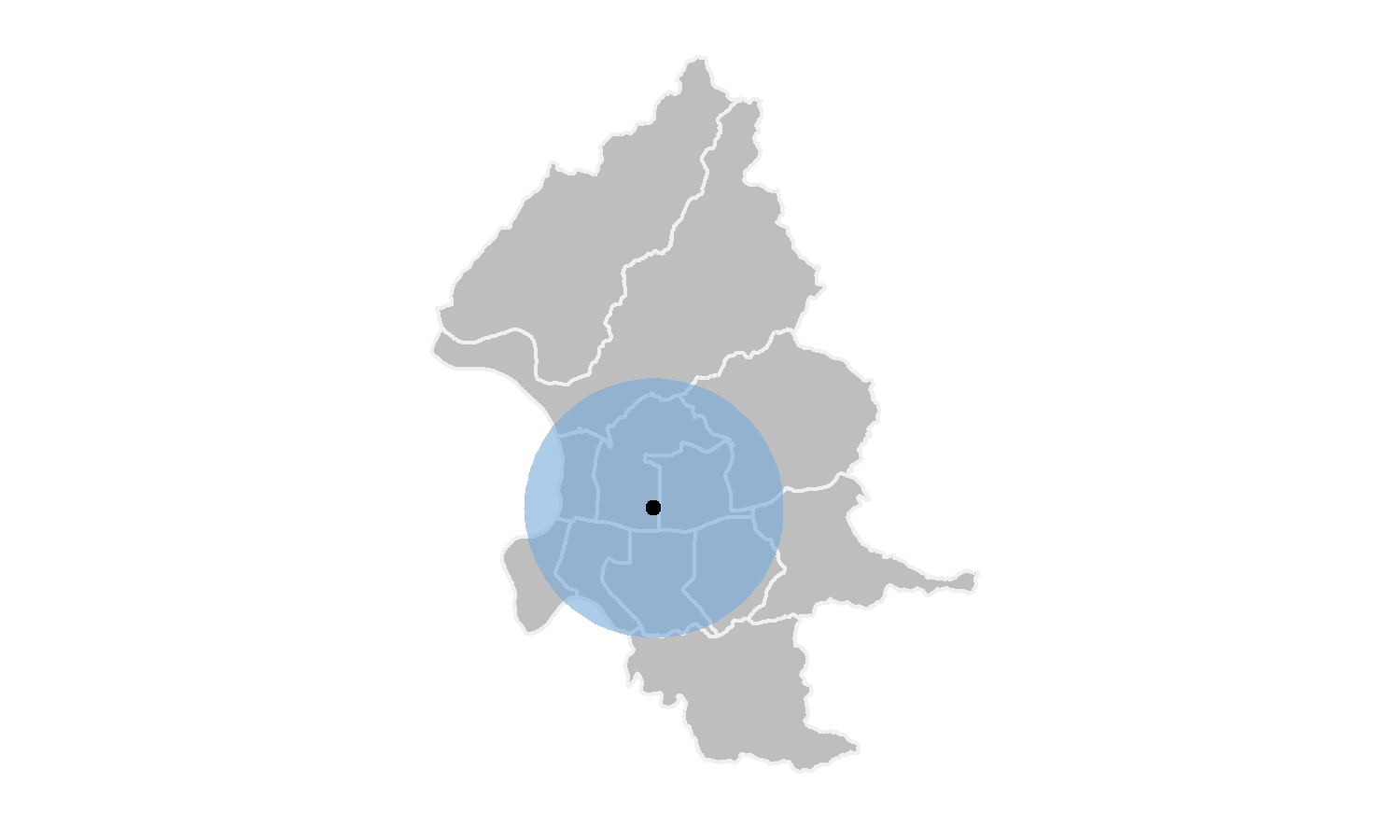
## 3143.041 3905.884From the results above, we can know that the mean of X is 304679.5, while the mean of Y is 2771747.9. Also the standard deviation of X and Y are 3143.041 and 3905.884 respectively. Thus, the standard distance would be \(\sqrt{(3143.041^2+3905.884^2)}=5013.45\) meters. Figure below shows the center and standard distance of Taipei YouBike.
There is another package called aspace that can calculate the center and standard distance directly. But very unfortunately, this package has been removed from CRAN recently. Thus, please download the zip file here, and place it into the same directory as your R script file. The installation code from the local is as follows.
install.packages("devtools")
devtools::install_local("./aspace-master.zip")
library(aspace)Now, let’s again use YouBike data to retrieve its center and standard distance by function mean_centre() and calc_sdd provided by package aspace.
youbike_center=mean_centre(points=taipei_youbike_coor)## id CENTRE.x CENTRE.y
## 1 1 304679.5 2771748youbike_sdd=calc_sdd(points=taipei_youbike_coor)## $id
## [1] 1
##
## $calccentre
## [1] TRUE
##
## $weighted
## [1] FALSE
##
## $CENTRE.x
## [1] 304679.5
##
## $CENTRE.y
## [1] 2771748
##
## $SDD.radius
## [1] 5016.196
##
## $SDD.area
## [1] 79049460We can find that the result from two methods are approximately the same. Note that $SDD.radius represents the standard distance, and it causes only 3 meters difference from what we calculate above. In addition, there is a function called CF() that can identify the central feature within a set of point locations. That is, the center of the points must be one of the points.
youbike_center_CF=CF(points=data.frame(taipei_youbike_coor))## id CF.x CF.y
## 1 1 304864.8 2770973# use left_join() to find out what the station is
left_join(youbike_center_CF, cbind(taipei_youbike, st_coordinates(taipei_youbike)), by=c("CF.x"="X", "CF.y"="Y"))%>%
select(StatnNm, CF.x, CF.y)## StatnNm CF.x CF.y
## 1 YouBike1.0_復興市民路口 304864.8 2770973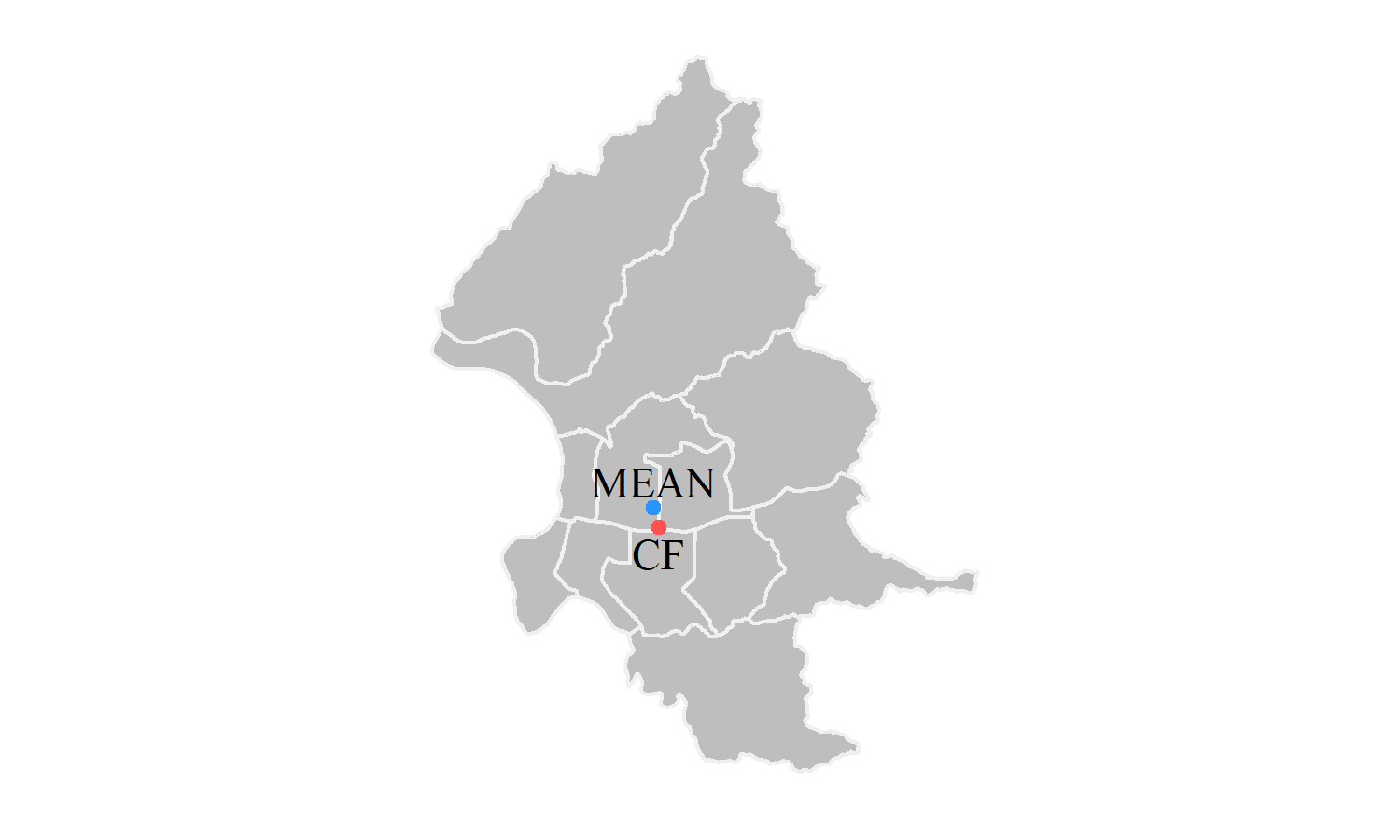
Besides the general calculation of center and standard distance, package aspace can also consider the weights. The general center can only represent the geographical position, but cannot reflect the one affected by the social and economic factors. Now let’s move on to the shapefile of Taipei village in the downloaded data, which contains the attribute of population for each village. And our purpose is to find out the “geographical centroid” and the “center of the population density” of each district in Taipei City. Obtaining these two values, we can compare the difference of two kind of points, and explain the implications.
For the centroid of town, simply use function st_centroid() to retrieve the center of each district. As for the calculation of weighted center, it is suggested to use for loop. First of all, we need to calculate the population density of each village, which equals to population divided by the area. Then, finding the centroid of each village by function st_centroid() to be the representative point of the village. Next, use function mean_centre() and set the parameters weighted=T and weights=..., to calculate the center of all the points revised by the weight of population density. And, also, apply function calc_sdd() to calculate the standard distance under the influence of weight. The code and result are shown below.
# import shapefile
village=read_sf("./data/taipei_map/taipei_village_map.shp")
weight_analysis=data.frame()
for (i in unique(village$TOWNNAME)){
# filter the town
village_dis=filter(village, TOWNNAME==i)
# find the centroid of town
town_center=st_centroid(filter(town, TOWNNAME==i))
town_center=st_coordinates(town_center)
# find the centroid of each village (representative points)
village_center=st_centroid(village_dis)
# retrieve the coordinate of each point
village_center_coor=st_coordinates(village_center)
# set the weights as population density
# population density = population / area
# st_area retrieves "unit" type data, and the unit is m^2, thus use as.numeric to convert it, and divide by 1,000,000
village_center_pd=mean_centre(points=village_center_coor, weighted=T, weights=(village_dis$PP/(as.numeric(st_area(village_dis))/1000000)))
vil_sdd_pd=calc_sdd(points=village_center_coor, weighted=T, weights=(village_dis$PP/(as.numeric(st_area(village_dis))/1000000)))
# store the result in the table
weight_analysis=rbind(weight_analysis, data.frame(TOWN=i, town_center, village_center_pd[2:3], vil_sdd_pd$SDD.radius))
}
head(weight_analysis)## TOWN X Y CENTRE.x CENTRE.y vil_sdd_pd.SDD.radius
## 1 文山區 307943.5 2764644 305750.9 2765138 1387.2986
## 11 中正區 302460.2 2769473 302261.5 2769187 1093.2534
## 12 信義區 307688.8 2769306 307545.2 2770010 1224.0450
## 13 大安區 304841.9 2768863 304819.4 2769310 1238.6796
## 14 萬華區 300190.7 2769123 300484.0 2769100 921.0697
## 15 南港區 311532.8 2769909 309988.0 2771236 1316.9046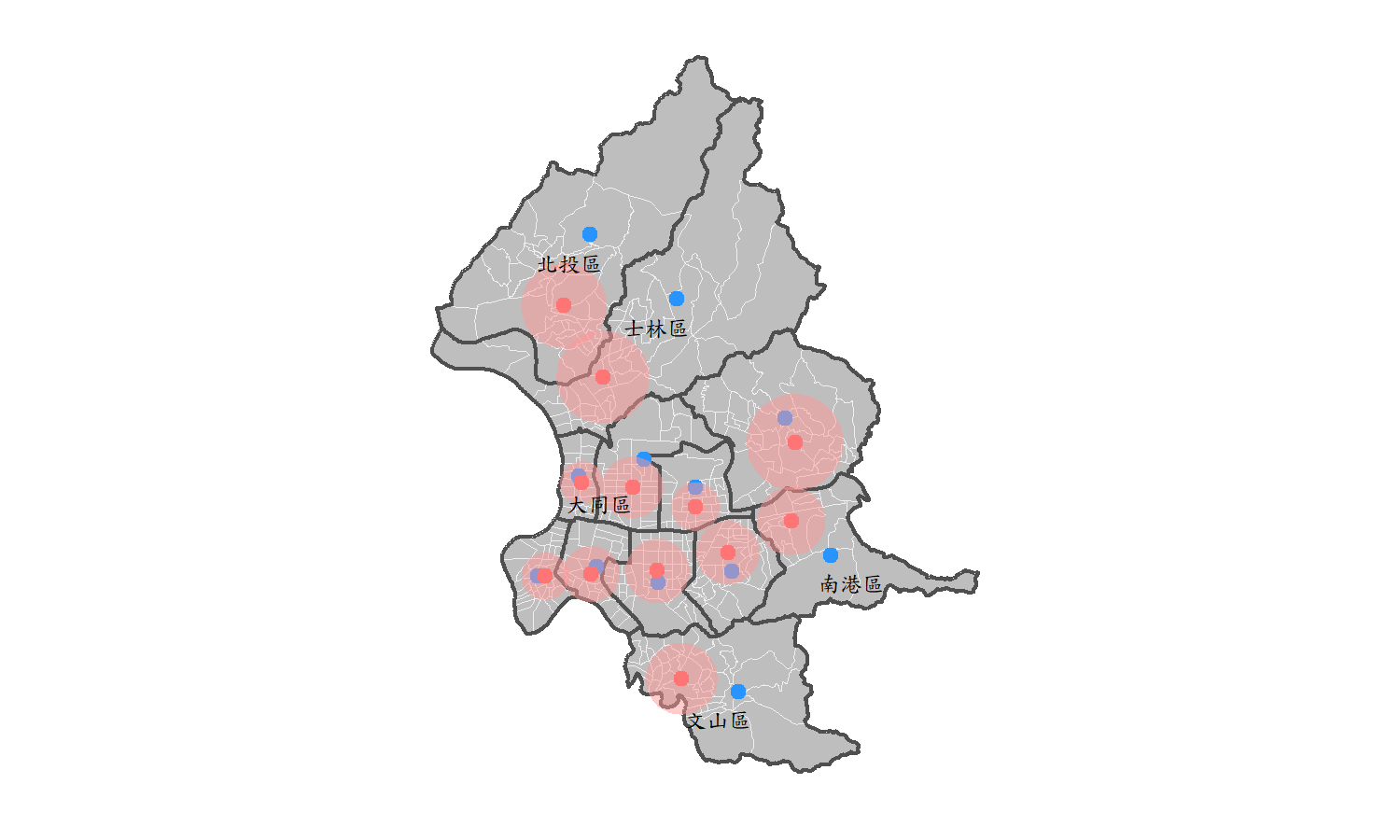
In the figure shown above, the blue dots represent the geographical centroid, which is the center of the polygons, while the red dots represent the centers weighted by the population density of each village in. Also, the red buffer means the weighted standard distance of each district. Take a closer look on the map. We can find that the district adjacent to the mountanious area, for instance 北投區, 士林區, 文山區, 南港區 have a larger difference between the geographical centroid and the population weighted center. Obviously, it is because people tend to live in plains with abundant living requirements. For the districts near CBD, such as 大同區, the differences between two points are slight.
This can further prove that using “geographical centroid” may not be meaningful, for it does not correspond to the real life. The weighted center can illustrate the population distribution, and even signify the land use of each district in Taipei City. To sum up, learning how to derive the weighted center may be an importaant issue in spatial analysis.
6.1.2 Quadrat Analysis
In the previous section, we have learned how to derive the centroid and the standard distance. For these two values, we can roughly realize the central tendency of the points distribution; however, we have no clear clue to tell whether the points distribution is dipersed, dense or random. Now, we would further discuss the density of the points by using a statistical method called Quadrat Analysis.
Quadrat analysis is a common method of exploring spatial pattern in the number of events. Specifically, in this analysis, we should first divide the study area into several grids. Then, count the number of points fall within each grid square. After counting the points, we should find a statistical measure to assess the distribution of point counts in grids, and determine whether the distribution is dipersed (uniform distribution), dense (cluster), or random (Poisson distribution). The steps are explained in detail with an simple example.
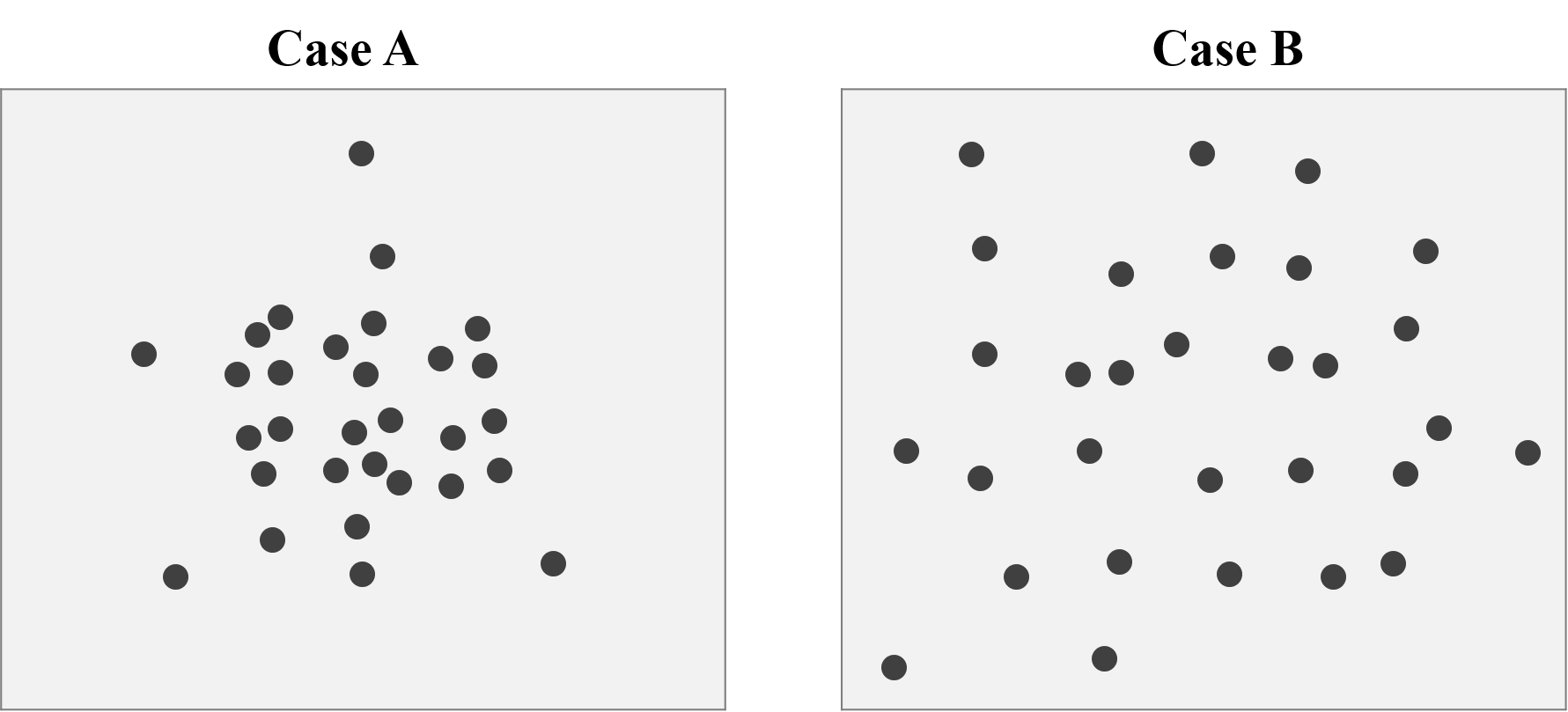
Figure below shows two cases of the point distribution. The number of points are the same (30) for two cases, but apparently the points pattern are totally different. We can easily observe that the distribution of Case A is dense, and the cluster is obvious, while the distribution of Case B is dipersed, and is approximately uniform distributed.
STEP 1: Make Grids
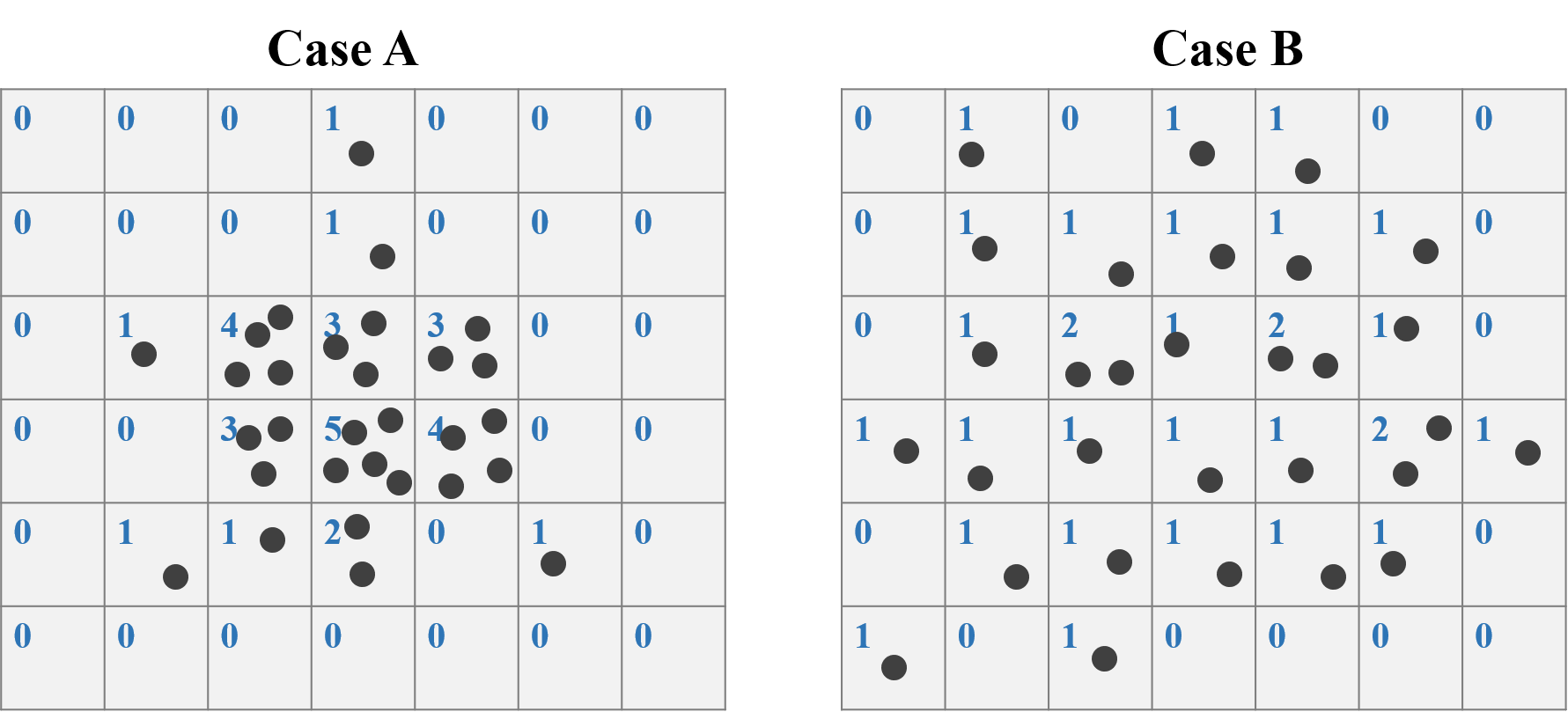
To do the Quadrat analysis, the initial step is to crop the study area into several grids, and count the number of points in each grid. Take Case A and B for instance. We crop the study area into 7*6=42 grids. For case A, the maximum number of points is 5, while only 2 for Case B.
STEP 2: Derive Mean & Variance
After counting the points in each grid in STEP 1, we need to further calculate the mean and variance of number of counts for all the grids. For Case A, the counts of mean is:
\[\frac{{(0+0+0+1+0+0+0)+(0+0+0+1+0+0+0)+(0+1+4+3+3+0+0)}+...}{6*7}=0.714\]
, and the variance is:
\[\frac{{(0-0.714)^2+(0-0.714)^2+(0-0.714)^2+(1-0.714)^2}+...}{6*7-1}=1.770\]
Also, the mean and variance of Case B is 0.714 and 0.355 respectively.
STEP 3: Caluculate VMR
Variance/mean ratio (VMR) is an index of dispersion, which is a common measure of assessing the degree of clustering or regularity in a point pattern.
\[VMR=\frac{\sigma^2}{\mu}\]
What does it mean if the variance is equal to mean (\(VMR=1\))? Remember the Poisson distribution? It is a discrete distribution that measures the probability of a given number of events happening in a specified time period (or the grid in spatial analysis). Mean and variance must be the same for this distribution!! Proof is attached here. With this feature, we can say that the number of points are random underlying the Poisson distribution.
The minimum value of VMR is 0, it occurs only if the variance is equal to 0. That is, all of the number of points in each grid is the same, and we can identify this point pattern as perfectly uniform distribution (extremely dipersed). On the contrary, if VMR is larger than 1, it implies that there is too much variation among counts, and we can say that the point pattern is clustering. Figure below summarizes the concept of VMR.
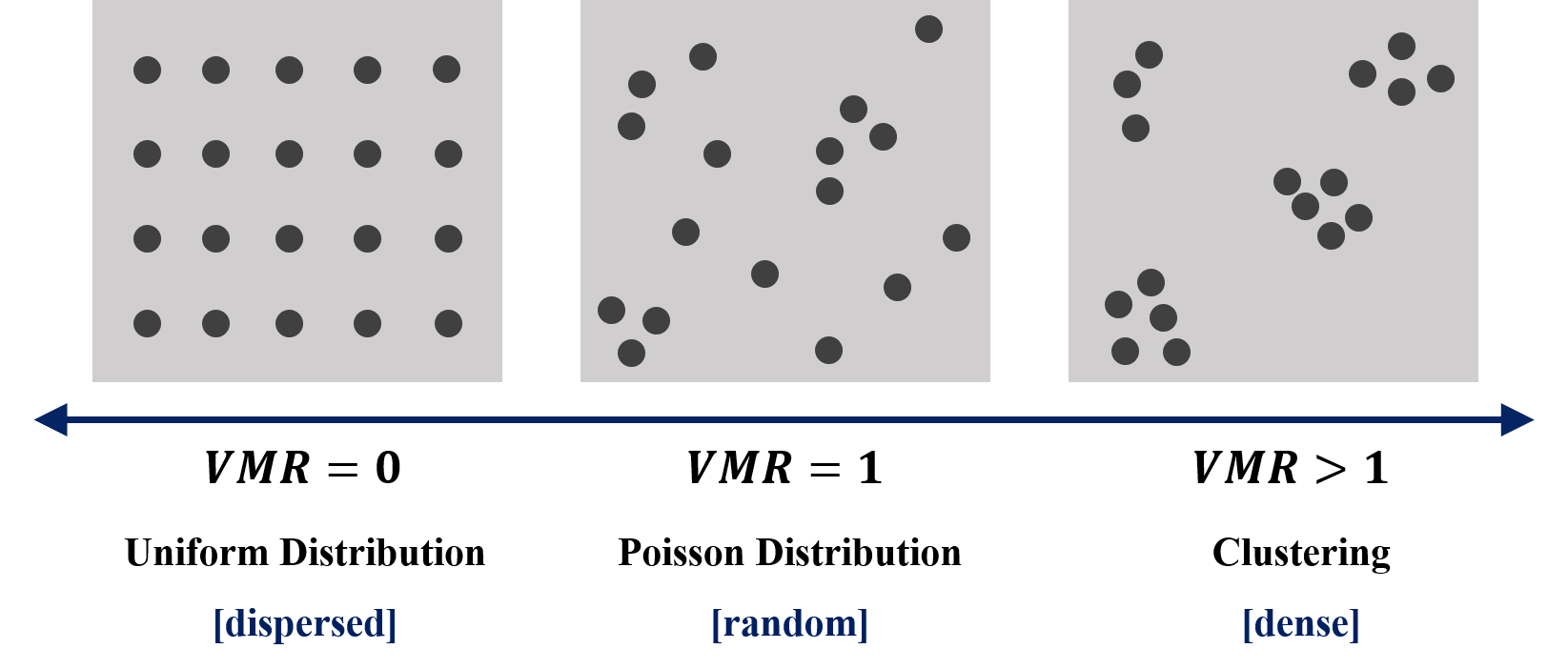
Thus, VMR of Case A is \(1.770/0.714=2.479\), while VMR of case B is \(0.355/0.714=0.497\). Based on the summary in the figure above, we can find that Case A is clustering, and Case B is dipersed.
STEP 4: Test Statistic
However, here comes a question. How do we distinguish between 1.001 and 1, or 0.999 and 1? Do the two values represent random or not? To solve the problem, we should conduct the hypothetical test to examine whether the test statistic result is significant. The null hypothesis is that the points are randomly distributed (\(VMR=1\)), namely, Poisson distribution, and it is chi-squared with \(N-1\) degrees of freedom. The test statistic of VMR is:
\[\chi^2=(N-1)*VMR\] , where \(N\) is the number of grid cells. After calculating \(\chi^2\), we can check for the chi-square table to examine whether to reject the null hypothesis. And note that VMR statistic test is a two-tail chi-squared test because there are two directions of deviations apart from the random distribution, that is uniform distribution, whose \(\chi^2\) would be low, and the clustering, whose \(\chi^2\) would be high. Thus, the acceptance of null hypothesis of an adequate fit if:
\[\chi^2_.975\leq\chi^2_{Observed}\leq\chi^2_.025\]
For Case A, the Chi-square is \((42-1)*2.479=101.639\). The degree of freedom is \(42-1=41\). Look up chi-square table, the critical value is 45.72 under p value is 0.025. (Or, please use qchisq(0.025, 41, lower.tail=F) in R to find out). Apparently, \(74.37>60.56\), Case A is significant clustering. For Case B, the Chi-square is \((42-1)*0.497=20.38\). The degree of freedom is also \(42-1=41\). Look up chi-square table, the critical value is 25.21 under p value is 0.975. (qchisq(0.975, 41, lower.tail=F)). And because \(20.38<25.21\), Case B is significant dispersed.
Now, let’s use YouBike data to perform quadrat analysis. Data needed has been downloaded previously. You placed the file in the same directory as the R script file. Click here to re-download the file if it is lost.